在DBMS中索引 -
- 索引用於通過最小化處理查詢時所需的磁片訪問次數來優化資料庫的性能。
- 索引是一種數據結構。它用於快速定位和訪問資料庫表中的數據。
索引結構
可以使用某些資料庫列創建索引。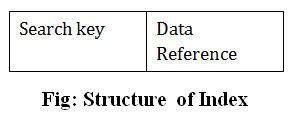
- 資料庫的第一列是搜索鍵,它包含表的主鍵或候選鍵的副本。主鍵的值按排序順序存儲,以便可以輕鬆訪問相應的數據。
- 資料庫的第二列是數據引用。 它包含一組指針,用於保存磁片塊的地址,可以在其中找到特定鍵的值。
索引方法
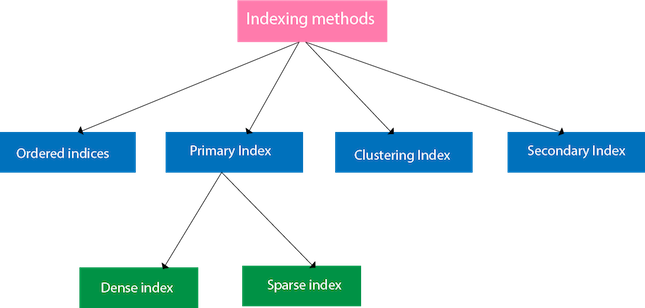
有序索引
通常對索引進行排序以使搜索更快,排序索引稱為有序索引。
示例: 假設有一個包含幾千條記錄的employee表,每條記錄的長度為10個位元組。 如果它們的ID是以1,2,3 ......等開頭,那麼如果要使用ID為543來搜索學生的資訊。
- 對於沒有索引的資料庫,需要從磁片塊開始搜索直到
543。 DBMS將在讀取543 * 10 = 5430位元組後讀取記錄。 - 在索引的情況下,直接使用索引進行搜索,DBMS將在讀取
542 * 2 = 1084位元組後讀取記錄,這與前一種情況相比非常少。
主鍵
- 如果索引是基於表的主鍵創建的,那麼它被稱為主索引。 這些主鍵對於每個記錄都是唯一的,並且在記錄之間包含
1:1的關係。 - 由於主鍵按排序順序存儲,因此搜索操作的性能非常高效。
- 主索引可以分為兩種類型:密集索引和稀疏索引。
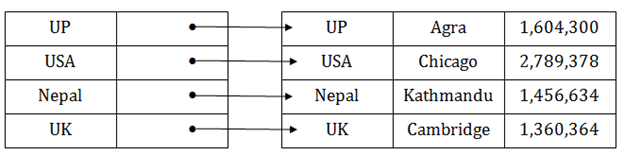
密集索引
- 密集索引包含數據檔中每個搜索鍵值的索引記錄,它使搜索更快。
- 在此,索引表中的記錄數與主表中的記錄數相同。
- 它需要更多的空間來存儲索引記錄本身。索引記錄具有搜索鍵和指向磁片上實際記錄的指針。
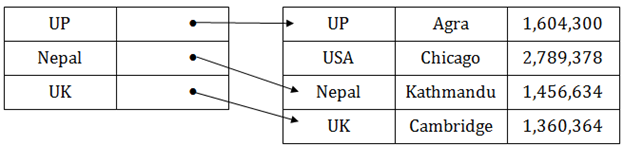
稀疏索引
在數據檔中,索引記錄僅針對少數專案出現。 每個專案都指向一個區塊。
在此,索引不是指向主表中的每個記錄,而是指向間隙中主表中的記錄。
聚類索引
- 聚簇索引可以定義為有序數據檔。 有時,索引是在非主鍵列上創建的,對於每個記錄可能不是唯一的。
- 在這種情況下,為了更快地識別記錄,將對兩列或更多列進行分組以獲取唯一值並從中創建索引。此方法稱為聚類索引。
- 對具有相似特徵的記錄進行分組,並為這些組創建索引。
示例: 假設公司在每個部門中包含多個員工。假設使用聚簇索引,其中屬於同一Dept_ID的所有員工都被視為在單個集群中,並且索引指針指向整個集群。 這裏Dept_ID是一個非唯一鍵。
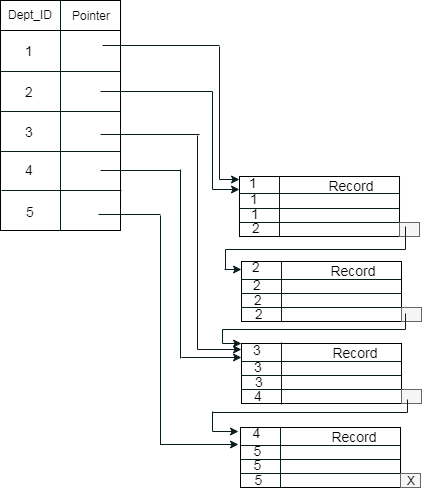
之前的架構很容易混淆,因為一個磁片塊由屬於不同集群的記錄共用。如果為單獨的集群使用單獨的磁片塊,那麼它是一種更好的技術。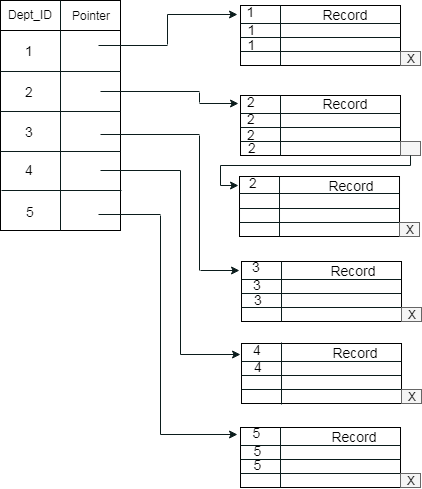
二級索引
在稀疏索引中,隨著表的大小增加,映射的大小也會增加。 這些映射通常保存在主記憶體中,因此地址獲取應該更快。 然後,輔助記憶體根據從映射獲得的地址搜索實際數據。 如果映射大小增加,那麼獲取地址本身會變慢。 在這種情況下,稀疏索引效率不高。 為了克服這個問題,引入了二級索引。
在二級索引中,為了減小映射的大小,引入了另一級索引。 在該方法中,最初選擇列的巨大範圍,使得第一級映射變小。 然後將每個範圍進一步劃分為更小的範圍。 第一級的映射存儲在主記憶體中,因此地址獲取更快。 第二級和實際數據的映射存儲在輔助記憶體(硬碟)中。
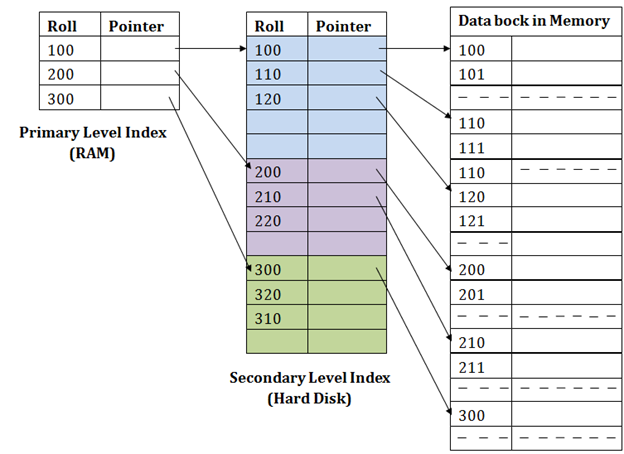
示例:
- 如果要在圖中找到卷
111的記錄,則它將搜索第一級索引中小於或等於111的最高條目。 這個級別將達到100。 - 然後在二級索引級別,它再次執行
max(111)<= 111並獲得110。現在使用地址是:110,它進入數據塊並開始搜索每個記錄,直到它達到111。 - 這是在此方法中執行搜索的方式。插入,更新或刪除也以相同的方式完成。