堆是平衡二叉樹數據結構,其中根節點鍵與它的子相比並設置相應在一種特殊情況。如果α有子節點β那麼 -
key(α) ≥ key(β)
作為父的值大於這個子,這個屬性會產生最大堆。基於該標準堆可以有兩種類型 -
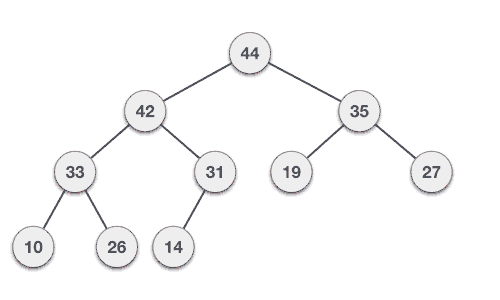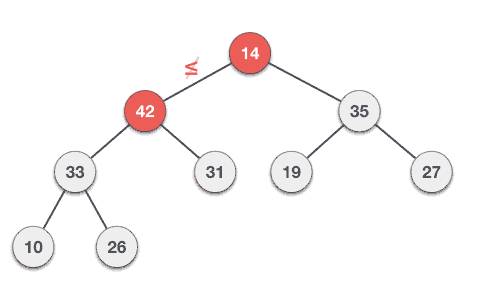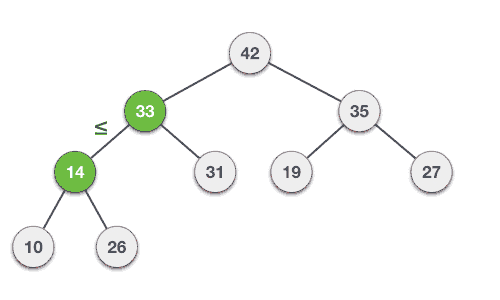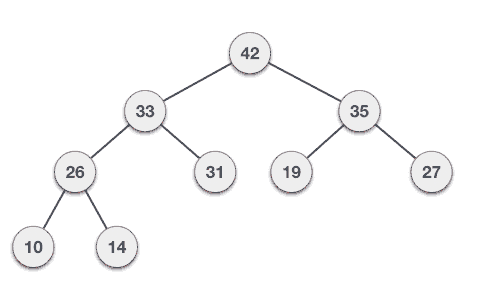
For Input → 35 33 42 10 14 19 27 44 26 31
-
最小堆 − 其中根節點的值小於或等於任一其子點。
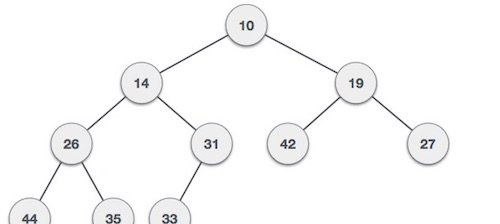
-
最大堆 − 其中根節點的值大於或等於任一其子節點。
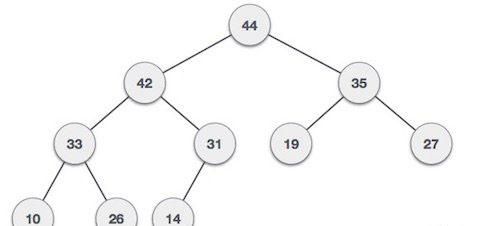
兩個樹都使用相同的輸入及到達順序構成。
最大堆構造演算法
我們將用同樣的例子來說明如何創建最大堆。程式創建最大堆與最小堆是類似,但使用最小值代替最大值。
我們將通過一次插入一個元素以導出最大堆演算法。在任何時間點,堆必須保持其性能。 當在插入時,假設插入在堆字段在樹中的節點。
Step 1 − 在堆的末尾創建新節點 Step 2 − 分配節點的新值 Step 3 − 比較其父與這個孩子節點的值 Step 4 − 如果父值小於子,那麼交換它們 Step 5 − 重複步驟3和4,直到堆屬性保存
注 − 在最小堆構造演算法,預計父節點的值要小於子節點。
我們先看一張卡通插圖來瞭解最大堆構建。拿我們之前用的相同輸入樣本。

最大堆刪除演算法
讓我們推導一個演算法的最大堆刪除。刪除最大(小)堆總是發生在根部去除最大(或最小)值。
Step 1 − 刪除 Step 2 − 分配節點的新值 Step 3 − 比較其父與這個孩子節點的值 Step 4 − 如果父值小於子,那麼交換它們 Step 5 − 重複步驟3和4,直到堆屬性保存