有很多演算法可以使用這些目錄來實現。 但是,選擇合適的目錄實現演算法可能會顯著影響系統的性能。
目錄實現演算法根據它們正在使用的數據結構進行分類。 目前主要使用兩種演算法。
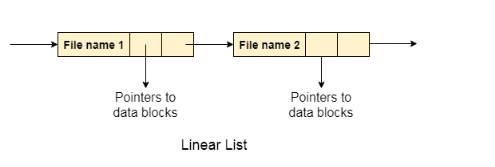
1. 線性列表
在這個演算法中,目錄中的所有檔都保持為單行列表。 每個檔都包含指向分配給它的數據塊的指針和目錄中的下一個檔。
特點
在創建新檔時,檢查整個列表是否新檔案名與現有檔案名匹配。 如果它不存在,則可以在開始或結束時創建該檔。 因此,尋找一個唯一的名字是一個大問題,因為遍曆整個列表需要時間。
該列表需要在檔的每個操作(創建,刪除,更新等)的情況下遍曆,因此系統變得低效。
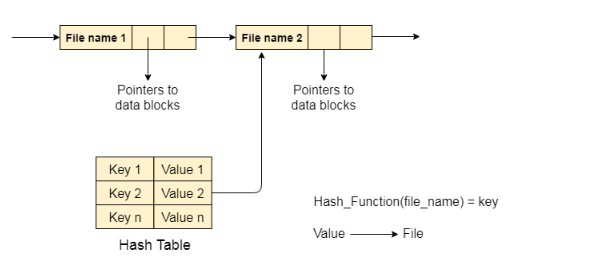
2. 哈希表
要克服目錄單鏈表實現的缺點,有一種替代方法就是哈希表。 這種方法建議使用散列表和鏈表。
目錄中每個檔的鍵值對都會生成並存儲在哈希表中。鍵可以通過在檔案名上應用散列函數來確定,而鍵指向存儲在目錄中的相應檔。
現在,搜索變得高效,因為整個列表在每次操作時都不會被搜索到。 只有哈希表項被使用該鍵檢查,並且如果找到的條目然後將使用該值來獲取相應的檔。