這裏有兩個數據集合在兩個不同的檔中,如下所示:
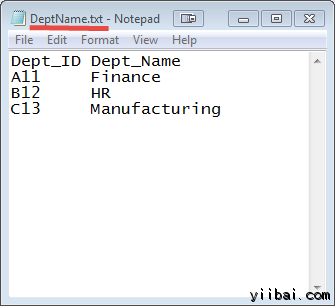
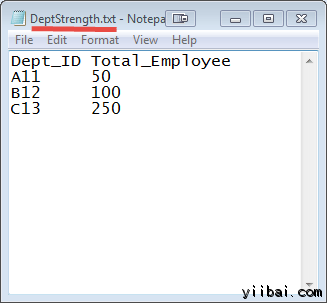
DEPT_ID 鍵在這兩個檔中常見的。
目標是使用 MapReduce 加入來組合這些檔。
輸入: 我們的輸入數據集是兩個txt檔:DeptName.txt 和 DepStrength.txt
前提條件:
- 本教程是在 Linux 上開發 - Ubuntu操作系統
- 已經安裝的Hadoop(本教程使用2.7.1版本)
- Java的開發運行環境已經在系統上安裝(本教程使用的版本是:1.8.0)
在我們開始實際操作之前,使用的用戶 'hduser_'(使用 Hadoop 的用戶)。
zaixian@ubuntu:~$ su hduser_
步驟
Step 1) 複製 zip 檔到您選擇的位置
hduser_@ubuntu:/home/zaixian$ cp /home/zaixian/Downloads/MapReduceJoin.tar.gz /home/hduser_/ hduser_@ubuntu:/home/zaixian$ ls /home/hduser_/
操作過程及結果如下:

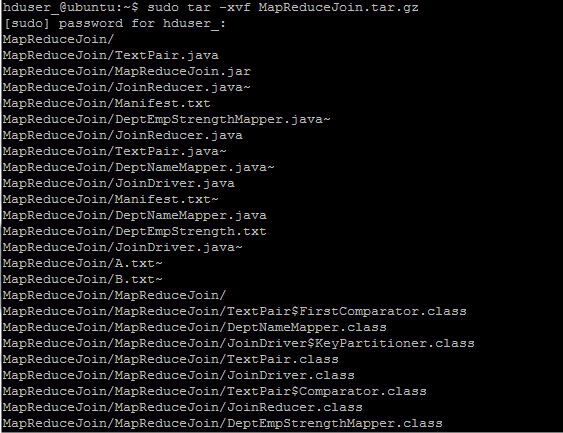
Step 2) 解壓縮ZIP檔,使用以下命令:
hduser_@ubuntu:~$ sudo tar -xvf MapReduceJoin.tar.gz
Step 3) 進入目錄 MapReduceJoin/
hduser_@ubuntu:~$ cd MapReduceJoin/
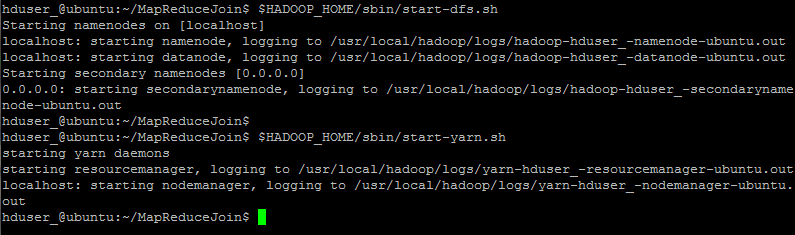
Step 4) 啟動 Hadoop
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/sbin/start-dfs.sh hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/sbin/start-yarn.sh
Step 5) DeptStrength.txt 和 DeptName.txt 用於此專案的輸入檔
這些檔需要使用以下命令 - 複製到 HDFS 的根目錄下,使用以下命令:
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/bin/hdfs dfs -copyFromLocal DeptStrength.txt DeptName.txt /
Step 6) 使用以下命令 - 運行程式
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/bin/hadoop jar MapReduceJoin.jar /DeptStrength.txt /DeptName.txt /output_mapreducejoin
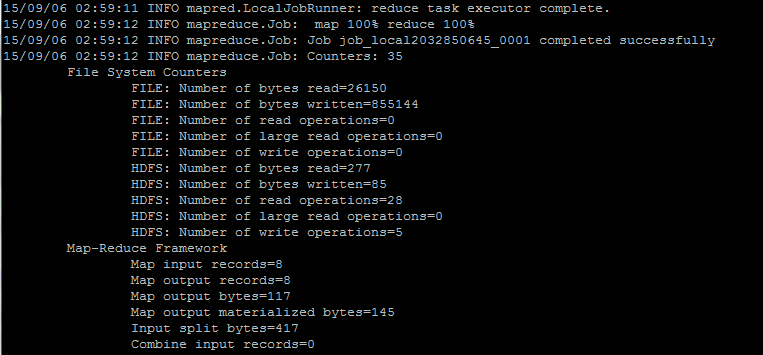
Step 7)
在執行命令後, 輸出檔 (named 'part-00000') 將會存儲在 HDFS目錄 /output_mapreducejoin
結果可以使用命令行介面可以看到:
hduser_@ubuntu:~/MapReduceJoin$ $HADOOP_HOME/bin/hdfs dfs -cat /output_mapreducejoin/part-00000

結果也可以通過 Web 介面查看(這裏我的虛擬機的IP是 192.168.1.109),如下圖所示:
現在,選擇 “Browse the filesystem”,並流覽到 /output_mapreducejoin
打開 part-r-00000
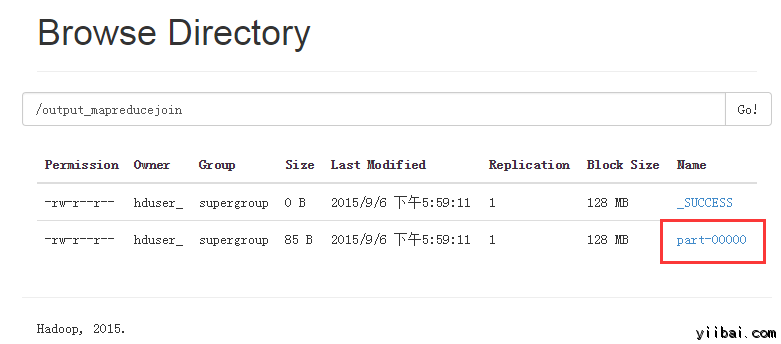
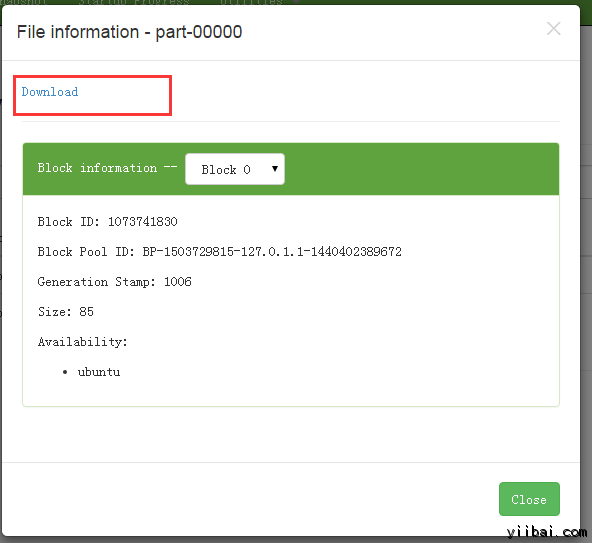
結果如下所示,點擊 Download 鏈接下載:
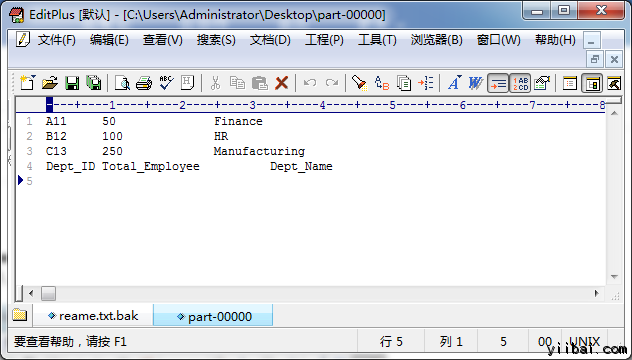
打開下載後的 檔,結果如下所示:
注:請注意,下一次運行此程式之前,需要刪除輸出目錄 /output_mapreducejoin
$HADOOP_HOME/bin/hdfs dfs -rm -r /output_mapreducejoin
另一種方法是使用不同的名稱作為輸出目錄。