在本教學中,將學習如何使用SQL Server CUBE生成多個分組集。
SQL Server CUBE簡介
分組集在單個查詢中指定數據分組。 例如,以下查詢定義表示為(品牌)的單個分組集:
SELECT
brand,
SUM(sales)
FROM
sales.sales_summary
GROUP BY
brand;
如果您沒有學習過GROUPING SETS的使用,可使用以下查詢創建sales.sales_summary表:
SELECT
b.brand_name AS brand,
c.category_name AS category,
p.model_year,
round(
SUM (
quantity * i.list_price * (1 - discount)
),
0
) sales INTO sales.sales_summary
FROM
sales.order_items i
INNER JOIN production.products p ON p.product_id = i.product_id
INNER JOIN production.brands b ON b.brand_id = p.brand_id
INNER JOIN production.categories c ON c.category_id = p.category_id
GROUP BY
b.brand_name,
c.category_name,
p.model_year
ORDER BY
b.brand_name,
c.category_name,
p.model_year;
即使以下查詢不使用GROUP BY子句,它也會生成一個空的分組集,表示為()。
SELECT
SUM(sales)
FROM
sales.sales_summary
GROUP BY
brand;
CUBE是GROUP BY子句的子句,用於生成多個分組集。 以下是CUBE的一般語法:
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
CUBE (d1, d2, d3);
在此語法中,CUBE根據在CUBE子句中指定的維度列:d1,d2和d3生成所有可能的分組集。
上面的查詢返回與以下查詢相同的結果集,該查詢使用GROUPING SETS:
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
GROUPING SETS (
(d1,d2,d3),
(d1,d2),
(d1,d3),
(d2,d3),
(d1),
(d2),
(d3),
()
);
如果在多維數據集中指定了N維列,則將具有2N個分組集。
通過部分使用CUBE可以減少分組集的數量,如以下查詢所示:
SELECT
d1,
d2,
d3,
aggregate_function (c4)
FROM
table_name
GROUP BY
d1,
CUBE (d2, d3);
在這種情況下,查詢生成四個分組集,因為在CUBE中只指定了兩個維列。
SQL Server CUBE示例
以下語句使用CUBE生成四個分組集:
(brand, category)
(brand)
(category)
()
參考以下查詢語句:
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
CUBE(brand, category);
執行上面查詢語句,得到以下結果: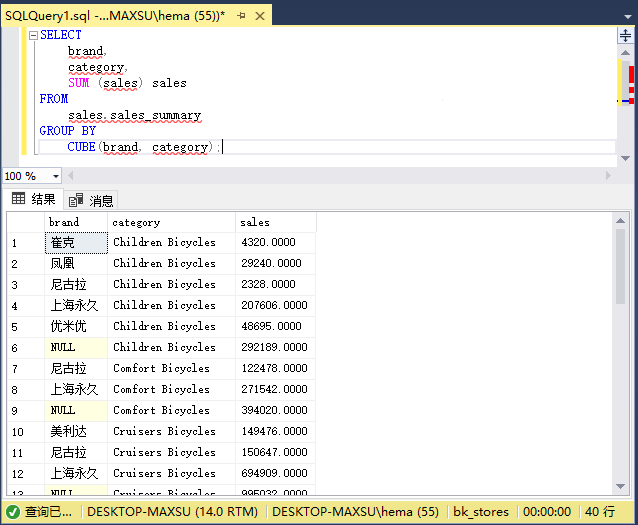
在此示例中,在CUBE子句中指定了兩個維列,因此,我們總共有四個分組集。
以下示例說明如何執行部分CUBE以減少查詢生成的分組集的數量:
SELECT
brand,
category,
SUM (sales) sales
FROM
sales.sales_summary
GROUP BY
brand,
CUBE(category);
執行上面查詢語句,得到以下結果: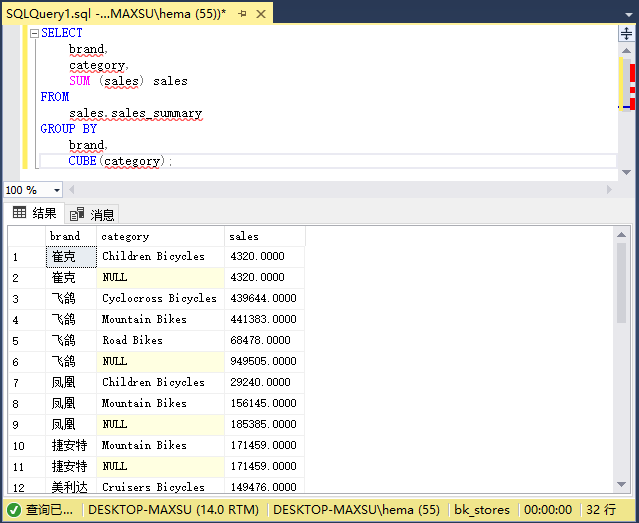
上一篇:
SQL Server數據分組
下一篇:
SQL Server子查詢語句