在本节中,您将学习如何通过XPath定位特定的Web元素 - 使用单个属性。
让我们考虑一个示例,通过XPath使用单个属性找到Google搜索引擎文本框。按照下面给出的步骤找到Google搜索引擎主页上提供的文本框。
- 在Firefox浏览器中打开URL :https://www.google.co.in/
- 右键单击示例网页上的文本框,然后选择“检查元素”
它将启动一个窗口,其中包含文本框开发中涉及的所有特定代码。
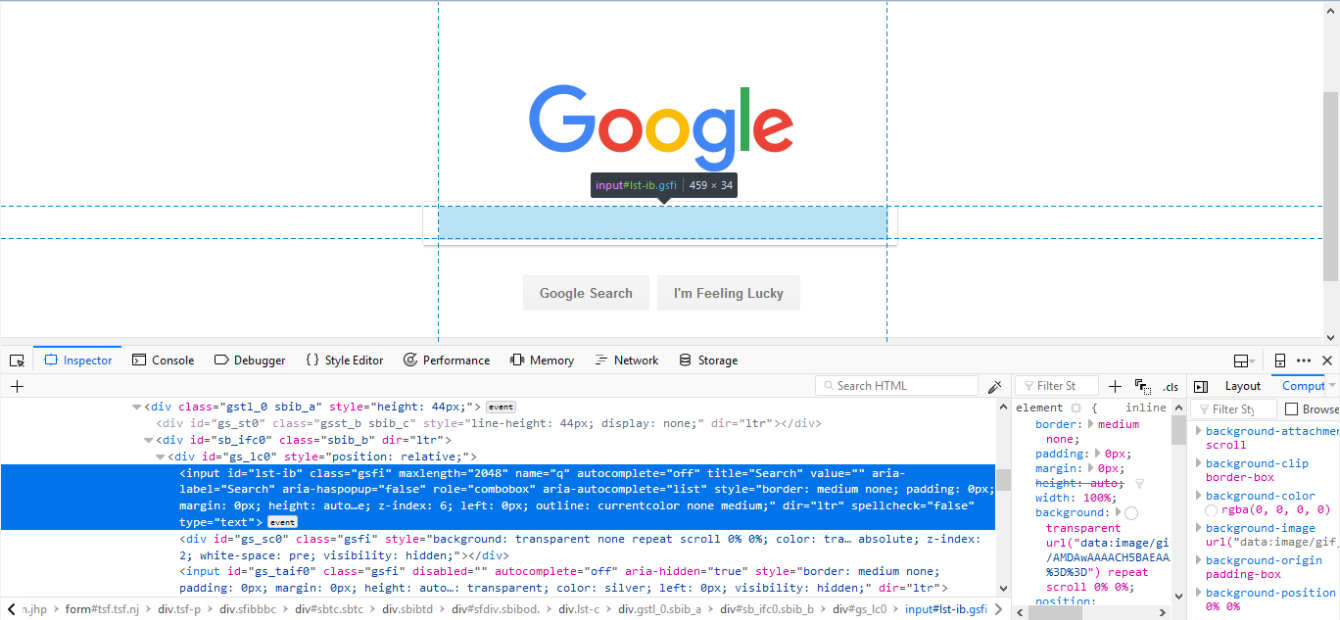
右键单击突出显示的代码,鼠标悬停在“复制”选项上。

选择 “Copy” -> “XPath”
注意:默认情况下,Firefox等浏览器会为XPath位置提供单个属性。
通过XPath单个属性定位元素的语法可以写成:
//<HTML tag>[@attribute_name='attribute_value']
或者 -
//*[@attribute_name='attribute_value']
注意:双斜杠后的
*用于匹配任何带有所需文本的标签。
复制所需的动态XPath位置并将其粘贴到Java代码之间,以通过XPath定位Web元素:
findElement(By.xpath("//*[@id="lst-ib"]"));